深度学习综合指南
这是一本面向初学者的深度学习综合指南。编写过程中借鉴了大量的经典教材、论文、文章,包括使用 AI 生成许多代码片段。教程主要分为四个阶段:
-
第 1 - 4 章:数学与深度学习基础
复习数学知识(函数、线性代数、统计学、微积分)。使用 Keras 高级 API 快速实现分类问题,理解什么是深度学习,包括数据、前向传播、反向传播、神经元、神经网络、优化器、损失函数、激活函数、梯度下降等基础概念。
熟悉常见的损失函数,并能够求解它们的导数。使用 NumPy ,结合多维数组,从头实现简单的分类问题,推导反向传播算法的具体逻辑。
-
第 5 - 6 章: 机器学习框架入门
系统学习主流机器学习框架 TensorFlow、PyTorch 和 JAX (以 PyTorch 为主) ,熟练使用张量和自动微分,加载简单数据集并完成训练,理解这些框架的相似性与差异,为后续实践打下扎实基础。
-
第 7 - 8 章: 经典网络与理论提升
使用 NumPy 实现卷积神经网络和循环神经网络,进一步加强数学理论知识。理解循环网络的限制,而发展出 LSTM 、GRU 网络,注意力机制。
深度学习的发展是循序渐进的,通过翻译经典论文的方式,理解 AlexNet 、ResNet、Unet 等网络。通过论文,可以清晰地看到人们是如何思考,并解决实际问题的。
-
第 9 - 12 章:实际应用与前沿探索
聚焦深度学习在文本、图片和语音生成中的实际应用,深入理解两大类架构:Transformer 和 Diffusion 模型。探索大模型的简单实现,并详细解析 Llama 模型的运行与关键原理。
认识 Transformer 是如何从循环网络进化而来,包括词嵌入、注意力机制、编码器-解码器架构。理解在 Transformer 基础上发展出来的模型,了解它们擅长的领域。
深入理解扩散模型的数学原理(随机微分方程、概率密度函数等),包括扩散和逆扩散是如何进行的。使用 MNIST 数据集,结合注意力机制,实现数字提示,可以生成照片的文生图模型。。
文本以清晰简洁的风格编写,使其成为任何有兴趣学习深度学习的人的理想资源。
01 认识机器学习:绘制直线
本章将回顾函数的基本概念,包括线性函数、多项式函数、幂函数、指数函数、有理函数、对数函数、三角函数,以及函数组合、函数变换、反函数等基本性质。
详细介绍 NumPy 科学计算库,使用各种方法创建 ndarray 数组,对数组进行索引和切片,并探讨数组之间的计算,例如广播、连接、乘法等运算。
使用传统解法和机器学习解法,求一条通过 100 个随机分布点的最佳拟合直线,即找到一条直线 \(y = m \cdot x + b\) 使得所有的点到直线的垂直距离之和(或平方和)最小。
1.1 函数基础
参考教材 Ch. 1 Introduction to Functions - Precalculus 2e | OpenStax 。
理解什么是函数,介绍线性函数和二次函数的基本性质,包括函数定义、变换率、函数图像、函数组合、函数变换、反函数等概念。
1.2 NumPy 介绍
翻译官方文档 NumPy documentation — NumPy v2.2 Manual 。
NumPy (Numerical Python) 是 Python 语言中基础的科学计算库,它提供多维数组对象,各种子类对象(如掩码数组和矩阵),以及对数组进行各种快速操作的函数,包括数学、逻辑、维度转换、排序、访问、I/O、离散傅里叶变换、基本线性代数、基本统计、随机模拟等。
- NumPy 数组计算库入门
- 复制 copy 和视图 view
- 数组创建:使用 Python 序列
- 数组创建:使用 NumPy 内置创建函数
- 数组创建:复制、连接、改变现有数组
- 数组创建:从磁盘读取
- 数组索引:indexing 整体介绍
- 数组索引:复习 range 和 slice 对象
- 基础索引:单个元素作为下标
- 基础索引:使用 slice 对象
- 基础索引:维度索引工具 ... 和 newaxis
- 高级索引:使用整形数组
- 高级索引:使用布尔数组
- 高级索引:基础与高级结合
- 字段索引:使用字符串 x['field-name']
- 迭代索引:x.flat 函数
- 变量索引:使用变量
- 索引数组赋值
- 数组的算术操作
- 数组广播
- 数据统计
- 修改数组形状
- 生成随机数
1.3 常见函数
参考教材 Precalculus 2e 第 3 、4 、5 章:
简单介绍后续机器学习经常碰到的函数,比如二次函数、有理函数、log 函数、对数函数、三角 (sin/cos) 函数等。
1.4 传统方程求解
使用传统方程进行求解,使用点到直线的距离公式,建立关于斜率的函数,通过求解函数最小值获取斜率值。
1.5 机器学习求解
使用机器学习的思维解决线性回归问题,理解线性回归的本质,以及它在多维空间的拓展。
02 深度学习原理
了解机器学习与传统编程的区别,理解深度学习原理,熟悉人工神经网络的训练过程,包括数据预处理、神经元、权重、损失函数、优化器、反向传播等概念。
教材《线性代数介绍》深入浅出地介绍了线性代数的核心概念,包括矩阵运算、向量空间、线性变换、正交性、特征值与特征向量等。
将日常生活中的常见表示(特征数据、文字、图片、视频、声音)转换为神经网络的数据输入,对数据进行一些预处理操作,手动实现常见的数据处理算法。
2.1 什么是机器学习
介绍什么是机器学习,它与传统编程的区别。深度学习是机器学习的一个子领域,它是一种从数据中学习表示的新方法,其强调学习连续的、越来越有意义的层。
2.2 人工神经网络
理解神经网络的各大组件,包括层、优化器、损失函数、目标值等。
2.3 线性代数
2.4 数据表示
2.5 数据操作
2.6 常见微型数据集
03 分类问题:Keras 求解
介绍统计学的基础知识,包括采样、数据统计、概率、正态分布等。使用标准正态函数,生成分类问题的随机分布点。
二分类问题是指在机器学习或统计学中,将数据划分为两个类别的分类任务。常见的二分类问题包括垃圾邮件分类(垃圾邮件与正常邮件)、疾病诊断(有病与无病)、图像分类(有目标与无目标)等。
多分类问题是机器学习中的一个常见任务,其目标是将输入数据分配到多个类别中的一个。例如给定一张图片,模型需要判断图片中的内容是猫、狗还是鸟。
本章主要使用 Keras 高级 API 来解决以上两个问题,进一步熟悉深度学习中常见的模块,包括模型、层、损失函数、优化器等。通过快速上手简单的示例,理解深度学习全流程,为后续详细介绍奠定基础。
3.1 统计学入门
参考教材 Introductory Statistics 2e
3.2 二分类问题
Keras 实现二分类问题
3.3 Keras 快速入门
全面但粗略地介绍 Keras 深度学习高级 API 。
3.4 图片分类
使用 Keras 进行图片分类。
3.5 其它分类问题
进一步熟悉 Keras ,解决其它类型的分类问题。
04 详解反向传播算法
复习导数(求微分)、链式法则、极值、偏导数等数学概念。通过 numpy 实现常见的激活函数和损失函数,并求解它们的导数。使用链式法则求解模型的梯度,理解权重是如何更新的。
手写 全连接神经网络 (Dense Neural Network, DNN) ,理解网络的训练过程,即求复合函数 h(g(f(weights, biases))) 的极值(极大或极小),实现几个简单的模型。
4.1 导数
翻译微积分教材 第 3 章 导数 。
4.2 激活函数
4.3 损失函数
4.4 梯度下降
4.5 手写神经网络
翻译文章 Machine Learning for Beginners: An Introduction to Neural Networks ,没有其它改动。
4.6 绘制曲线
4.7 坐标点分类
05 张量和自动微分
5.1 快速预览
5.2 张量表示
5.3 自动微分
5.4 micrograd
复现 micrograd 库的内容。
5.5 tinygrad 分析
06 训练神经网络
使用 TensorFlow / PyTorch / JAX 进行训练,熟练使用主流机器学习库。介绍如何对训练过程进行优化。
6.1 NumPy
6.2 TensorFlow
6.3 PyTorch
6.4 JAX
07 卷积神经网络
7.1 认识卷积网络
7.2 手写卷积网络
7.3 AlexNet 论文
7.4 U-Net 论文
翻译论文 U-Net: Convolutional Networks for Biomedical Image Segmentation
7.5 ResNet 论文
08 循环神经网络
循环神经网络 (Recurrent Neural Network, RNN) 是一种用于处理序列数据的神经网络架构,与传统的前馈神经网络不同,RNN 在每一时刻的输出不仅依赖当前输入,还依赖于前一时刻的隐藏状态,从而能够捕捉序列中的时间依赖关系。
8.1 循环神经网络入门
翻译文章 An Introduction to Recurrent Neural Networks for Beginners,主要有以下几点区别:
-
1. 在梯度计算阶段增加更加详细解释,推导 softmax 函数的导数。
-
2. 增加 8.1.9 小节 使用 PyTorch 实现这个简单的示例。
8.2 RNN 详解
翻译系列文章:
-
Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
-
Recurrent Neural Networks Tutorial, Part 2 – Implementing a RNN with Python, Numpy and Theano
-
Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
-
Recurrent Neural Networks Tutorial, Part 4 – Implementing a GRU and LSTM RNN with Python and Theano
主要有如下区别:
-
删除过时的 Theano 机器学习库部分,采用流行的 PyTorch 实现。
8.3 长短期记忆网络
8.4 GRU 网络
翻译论文 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
8.5 WMT 数据集
处理欧洲议会会议记录 (Europarl) 第 7 版中英语-德语、英语-法语翻译数据集,使用 BLEU 方法进行评估。
翻译论文 BLEU: a Method for Automatic Evaluation of Macine Translation
8.6 RNN 翻译
参考 GitHub 网站的 pytorch-seq2seq 仓库,引用以下几篇论文:
-
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
-
Neural Machine Translation by Jointly Learning to Align and Translate
使用 PyTorch 和 TorchText 实现一些序列到序列 (seq2seq) 模型的教程。
8.7 Seq2Seq 论文
翻译论文 Sequence to Sequence Learning with Neural Networks
8.8 Word2Vec 论文
翻译论文 Efficient Estimation of Word Representations in Vector Space
09 Transformer 架构
提到大语言模型 (LLM) 背后的技术,很多人就会想到 Attention Is All You Need 这篇论文,然后以论文里的模型架构图(如下所示)开始向新手讲述其原理。
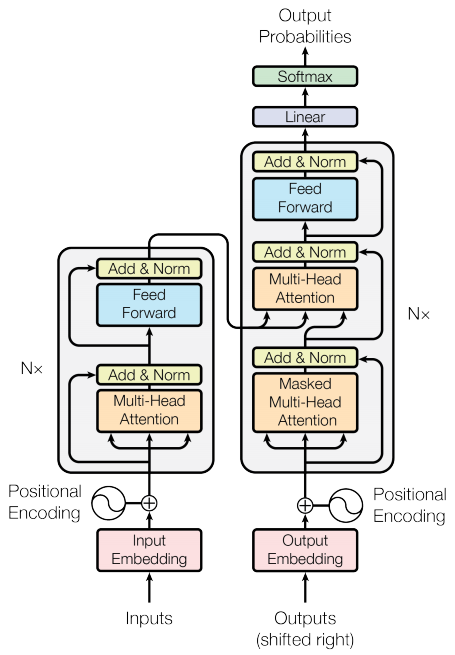
即使你有神经网络的基础知识,当听到编码器-解码器架构,词嵌入、位置编码、多头注意力、自注意力等这些高级名词时,很容易因为太多抽线概念揉在一起,导致无法理解。
Transformer 架构的出现并不是一蹴而就的,如果你跟随机器翻译 (Machine Translate) 的历史,就会发现技术是层层递进的,就像地球生命的演化过程。从简单到复杂,最后彻底掌握大语言模型技术。
本章就是以技术演化的结构来编写,通过相关论文逐步解释 Transformer 架构,并带有大量的代码实现。
最初神经网络这个名词带有人们强烈想要模仿人类大脑的结构获取智能的想法,在上个世纪它经历了曲折的发展过程,可以查看维基百科 人工智能的历史 。
1997 年,发表论文 LONG SHORT-TERM MEMORY ,属于普通 RNN 网络的改进版,用于解决长距离依赖问题。
1998 年,Yann LeCun 发表论文 Gradient-Based Learning Applied to Document Recognition ,将梯度引入到神经网络,解决了手写数字识别问题。
这个时间段深度学习的理论基本已经确定,主要限制于硬件水平无法将理论应用于大规模网络。
2007 年英伟达公司提出统一计算架构 (CUDA) ,用于处理通用的计算任务。
计算机技术的不断发展,许多研究者此时已经看到重启深度学习的曙光,2009 年,李飞飞团队发表论文 ImageNet: A large-scale hierarchical image database ,ImageNet 规模和多样性远远大于当时的图像数据集,为计算机视觉的研究人员提供无与伦比的机会。
2012 年,Alex Krizhevsky 等人发表论文 ImageNet Classification with Deep Convolutional Neural Networks ,使用 GPU 构建了当时最大的卷积神经网络。在 ILSVRC-2012 比赛中将 Top-5 错误率从 26.2% 降低到 15.3% ,使人们意识到深度神经网络巨大的潜力。
技术在不断推进,2015 年,何凯明等人发表论文 Deep Residual Learning for Image Recognition ,提出残差架构,可以训练更深的网络。ILSVRC-2015 的错误率降低到 3.57%,相当于彻底解决该问题。
具体到机器翻译方面,因为文本有先后位置关系,当时最流行的技术是使用 LSTM 网络,这个时期有非常多的论文在研究:
A Neural Probabilistic Language Model
Recurrent neural network based language model
On the difficulty of training Recurrent Neural Networks
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Generating Sequences With Recurrent Neural Networks
在这里,我们需要理解 RNN 的基本原理是什么,它的核心是隐藏状态,如下图所示:
用 RNN 对文本进行分类
用 RNN 生成文本
在这里我们应该学会文本的预处理,词嵌入。
在统计机器翻译中,我们需要初步理解 编码器-解码器架构,以及什么是短语表示。
9.1 注意力机制
采用教材《动手学深度学习》第 10 章 注意力机制
9.2 机器翻译论文
翻译论文 Neural Machine Translation by Jointly Learning to Align and Translate
9.3 注意力论文
翻译论文 Effective Approaches to Attention-based Neural Machine Translation
9.4 Transformer 论文
生成式 (Generative)
生成式方法的目标是在已知的样本数据上学习其特征分布,然后生成具有相似特征的全新数据,包括:稳定扩撒、神经风格迁移、DeepDream、卷积生成对抗网络、Pix2Pix 、CycleGAN 。
10.1 自动编码器
10.2 神经风格迁移
10.3 DeepDream
10.4 生成对抗网络
生成对抗网络 (Generative Adversarial Networks, GANs) 通过对抗过程训练两个网络,生成器 (Generator) 学习创建看起来真实的图像,而鉴别器 (Discriminator) 学习区分真实图像和假图像。
10.5 Pix2Pix
10.6 CycleGAN
图片扩散 (Diffusion)
翻译教程 Mathematical Foundation of Diffusion Generative Models 。在本教程中,我们介绍了扩散生成模型的数学基础,有以下目标:
得分函数作为数据分布的梯度;
得分函数可以计算逆扩散过程;
通过去噪分数匹配来学习得分函数;
用神经网络近似得分函数;
从扩散模型中抽样。
使用低维数据 (2D) 中的具体示例并将其应用于高维数据(点云或图像)。
11.1 扩散模型的数学基础
翻译教程 Understanding Stable Diffusion from "Scratch"
11.2 马尔可夫算法
11.3 热力学过程
11.4 去噪扩散模型
11.5 贝叶斯
11.6 稳定扩散
11.7 从头构建
大语言模型 (LLM)
12.1 语言模型
翻译系列文章 From Transformer to LLM: Architecture, Training and Usage 。
12.2 图解 GPT2
翻译文章 The Illustrated GPT-2 (Visualizing Transformer Language Models) 。
12.3 nanoGPT
nanoGPT 是最简单、最快的中型 GPT 训练/微调存储库,优先考虑实用性而非教育性。介绍 Llama 开源模型,包括如何访问模型、托管、操作方法和集成指南。