7.4 Transformer 翻译模型
使用 Transformer 和 Keras 进行神经机器翻译!
创建日期: 2025-04-15
本教程演示如何创建和训练 序列到序列 (Seq2Seq) 的 Transformer 模型,它将葡萄牙语翻译成英语。Transformer 最初在论文 Attention is all you need 中提出,可以查看《深度学习综合指南》第 9.4 节 Transformer 论文 的内容。
Transformer 是一种深度神经网络,它利用 自注意力机制 (Self-attention) 取代了 CNN 和 RNN 。自注意力机制让 Transformer 能够轻松地在输入序列之间传递信息。
正如 Google AI 博客文章 中所解释的那样:
机器翻译的神经网络通常包含一个编码器,用于读取输入句子并生成其表示。然后,解码器参考编码器生成的表示,逐字生成输出句子。Transformer 首先为每个单词生成初始表示或嵌入...然后它使用自注意力机制聚合来自所有其它单词的信息,根据整个上下文为每个单词生成一个新的表示,由下图填充的球表示。这个过程对所有单词并行重复多次,依次生成新的表示:

需要消化的内容很多,本教程的目标是将其分解为易于理解的部分。在本教程中,我们将:
-
准备数据;
-
实现必要的组件:
- 位置嵌入;
- 注意力层;
- 编码器和解码器。
-
构建和训练 Transformer ;
-
生成翻译;
-
导出模型。
为了充分利用本教程,如果您了解 第 7.2 节 文本生成 和 注意力机制 的知识,这将很有帮助。
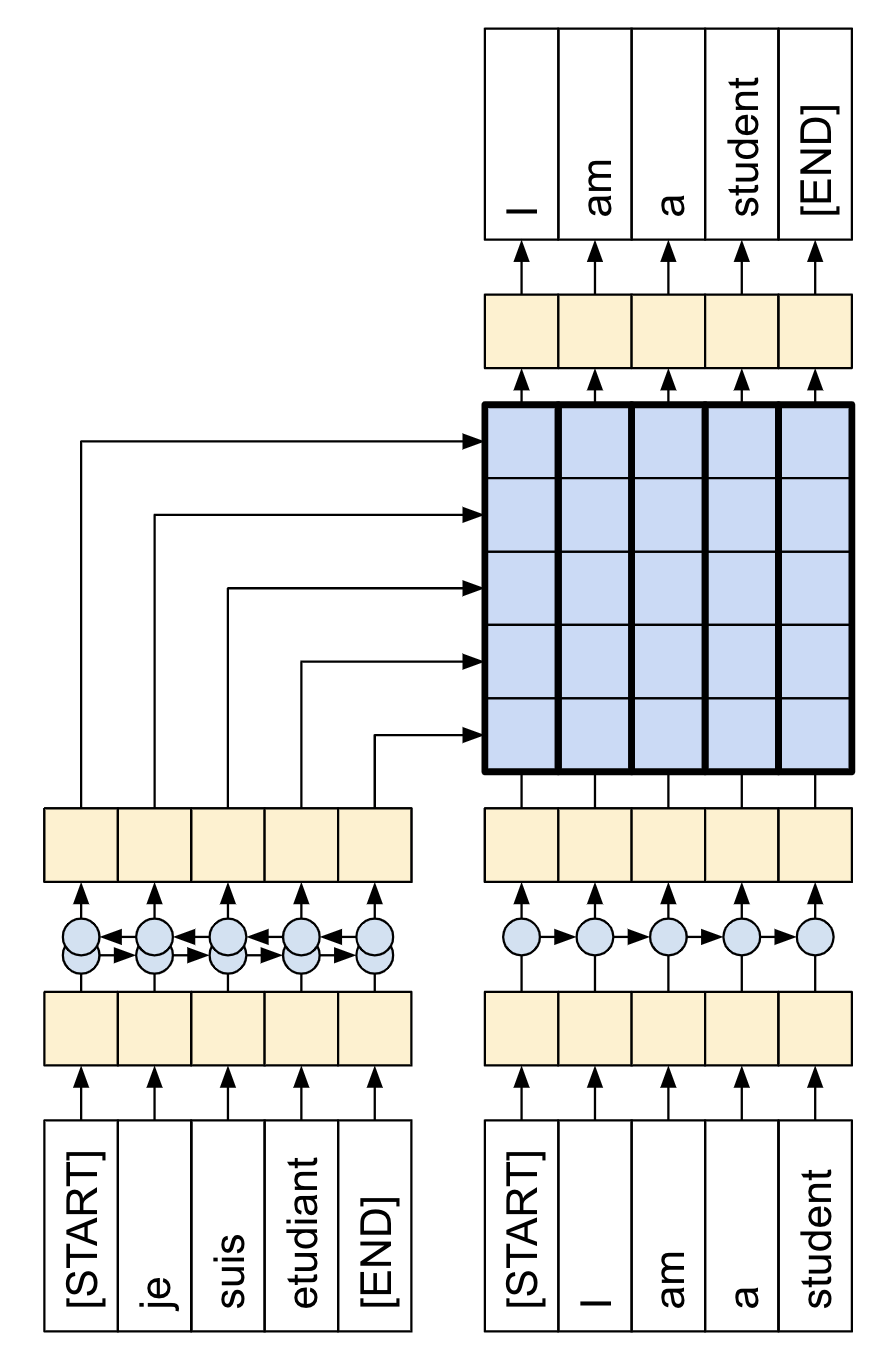
Transformer 是一种序列到序列的编码器-解码器模型,类似于 第 7.3 节 Seq2Seq 翻译模型 中的模型。单层 Transformer 需要编写更多代码,但与编码器-解码器 RNN 模型几乎相同,如下图所示展示带有注意力的 RNN 模型:
唯一的区别是 RNN 层被替换为自注意力层。本教程构建了一个 4 层 Transformer,它更强大,但从根本上来说并不更复杂。如下图展示单层 Transformer 模型:
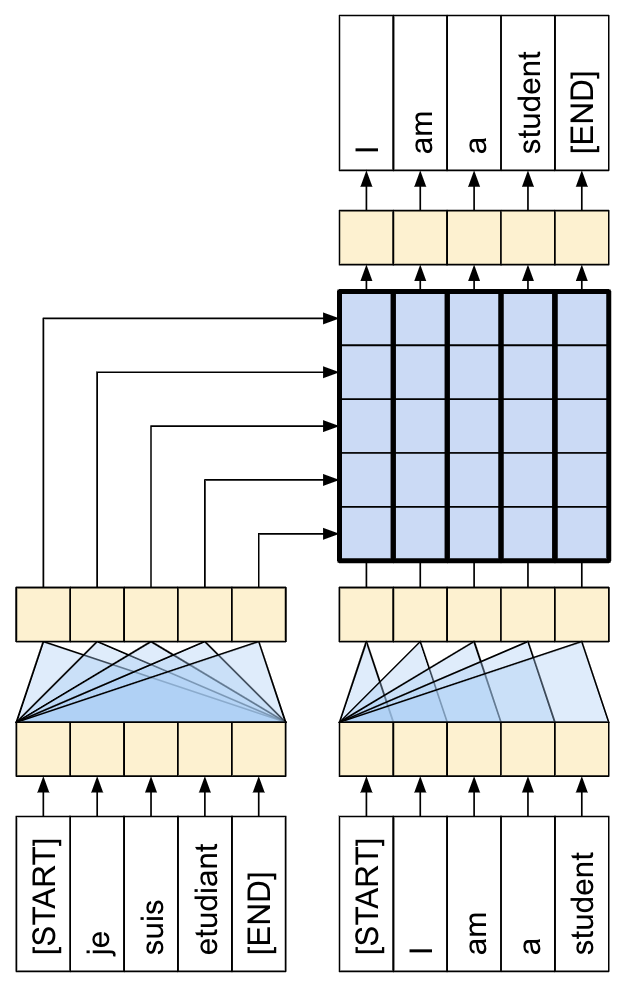
训练完模型后,我们可以输入葡萄牙语句子并返回英语翻译。可以看到生成的可视化注意力权重:
7.4.1 为何如此重要
-
Transformer 擅长对序列数据(例如自然语言)进行建模。
-
与循环神经网络 (RNN) 不同,Transformer 是可并行化的。这使得他们在 GPU 和 TPU 等硬件上非常高效。主要原因是 Transformer 用注意力机制取代了循环,计算可以并行,而不像 RNN 那样串联计算。
-
与 RNN(如 Seq2Seq)或卷积神经网络 (CNN) 不同,Transformer 能够捕获输入或输出序列中远距离位置之间的上下文和依赖。因此,长连接可以被学习。在每一层中注意力机制允许每个位置访问整个输入,而 RNN 或者 CNN ,信息需要经过许多处理步骤才能移动很长距离,这使得学习变得困难。
-
Transformer 不对数据中的时空关系做任何假设,这对于处理一组对象非常理想。
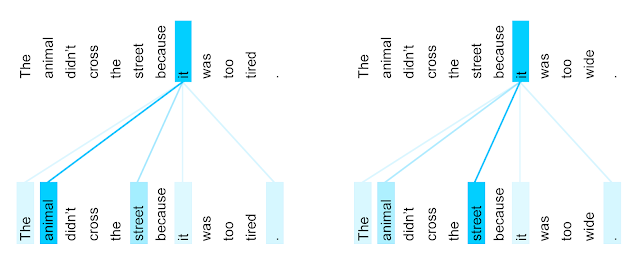
下图展示在英语到法语上训练的Transformer 的第 5 层和第 6 层,单词 "it" 的编码器自注意力分布(八个注意力头之一):
7.4.2 设置
需要安装 TensorFlow Datasets 下载数据集,和 TensroFlow Text 进行文本预处理,导入必要的模块:
from matplotlib import pyplot
import tensorflow as tf
import tensorflow_text
import tensorflow_datasets as tfds
import keras
import numpy7.4.3 数据处理
下载数据集和字词标记器,将它们生成一个 tf.data.Dataset 结构体。
7.4.3.1 下载数据集
使用 TensorFlow Datasets 加载 葡萄牙语-英语翻译数据集,这个数据集包含接近 52000 个训练,1200 验证和 1800 个测试样本:
examples, metadata = tfds.load('ted_hrlr_translate/pt_to_en',
with_info=True,
as_supervised=True)
train_examples, val_examples = examples['train'], examples['validation']TensorFlow Datasets 返回 tf.data.Dataset 对象,它可以产生成对的文本示例 (葡萄牙语-英语) :
for pt_examples, en_examples in train_examples.batch(3).take(1):
print('> Examples in Portuguese:')
for pt in pt_examples.numpy():
print(pt.decode('utf-8'))
print('> Examples in English:')
for en in en_examples.numpy():
print(en.decode('utf-8'))> Examples in Portuguese: e quando melhoramos a procura , tiramos a única vantagem da impressão , que é a serendipidade . mas e se estes fatores fossem ativos ? mas eles não tinham a curiosidade de me testar . > Examples in English: and when you improve searchability , you actually take away the one advantage of print , which is serendipity . but what if it were active ? but they did n't test for curiosity .
7.4.3.2 设置标记器
我们已经加载了数据集,接下来需要将文本 标记 (Tokenize) ,这样每个元素可以使用 标记 (Token) 或者标记 ID(数字)表示。
标记化是一个将文本分解成标记的过程。取决于标记器,这些标记可以表示句子片段、单词、子单词或者字符。要了解更多标记器的知识,可以访问 Tokenizing with TF Text 文档。
本教程使用的是 Subword tokenizers 中的内置标记器。它优化了两个 text.BertTokenizer 对象(一个是英语,一个是葡萄牙语),使用 TensorFlow 的 save_model 格式导出。
与 原始论文 5.1 小节 不同,它们对源句子和目标句子使用单 字节对 (Byte-pair) 标记器,总词汇量为 37000 。
下载、解压、导入 save_model 格式:
model_name = 'ted_hrlr_translate_pt_en_converter'
keras.utils.get_file(
f'{model_name}.zip',
f'https://storage.googleapis.com/download.tensorflow.org/models/{model_name}.zip',
cache_dir='.', cache_subdir='', extract=True)
tokenizers = tf.saved_model.load('ted_hrlr_translate_pt_en_converter_extracted/' + model_name)tf.saved_model 包含两个文本标记器,一个是英语,一个是葡萄牙语,它们都有相同的方法。
tokenize 方法将一批字符串转换为填充的标记 ID ,此方法在标记之前拆分标点符号、小写字母并对输入进行 Unicode 规范化。该标准化在此处不可见,因为输入数据已经标准化:
print('> This is a batch of strings:')
for en in en_examples.numpy():
print(en.decode('utf-8'))encoded = tokenizers.en.tokenize(en_examples)
print('> This is a padded-batch of token IDs:')
for row in encoded.to_list():
print(row)> This is a padded-batch of token IDs: [2, 72, 117, 79, 1259, 1491, 2362, 13, 79, 150, 184, 311, 71, 103, 2308, 74, 2679, 13, 148, 80, 55, 4840, 1434, 2423, 540, 15, 3] [2, 87, 90, 107, 76, 129, 1852, 30, 3] [2, 87, 83, 149, 50, 9, 56, 664, 85, 2512, 15, 3]
detokenize 方法尝试将这些标记 ID 转换回人类可读的文本:
round_trip = tokenizers.en.detokenize(encoded)
print('> This is human-readable text:')
for line in round_trip.numpy():
print(line.decode('utf-8'))底层 lookup 方法将标记 ID 转换为标记文本:
print('> This is the text split into tokens:')
tokens = tokenizers.en.lookup(encoded)
print(tokens)输出展示了 子词 (Subword) 标记器可以对单子进行分割:
> This is the text split into tokens:
<tf.RaggedTensor [[b'[START]', b'and', b'when', b'you', b'improve', b'search', b'##ability',
b',', b'you', b'actually', b'take', b'away', b'the', b'one', b'advantage',
b'of', b'print', b',', b'which', b'is', b's', b'##ere', b'##nd', b'##ip',
b'##ity', b'.', b'[END]'] ,
[b'[START]', b'but', b'what', b'if', b'it', b'were', b'active', b'?',
b'[END]'] ,
[b'[START]', b'but', b'they', b'did', b'n', b"'", b't', b'test', b'for',
b'curiosity', b'.', b'[END]'] ]>
比如单词 searchability 分解成为 search 和 ##ability ,单词 serendipity 分解成 s , ##ere , ##nd , ##ip 和 ##ity 。
需要注意的是标记的文本包含 [START] 和 [END] 两个标记。
数据集中每个示例的标记分布如下:
lengths = []
for pt_examples, en_examples in train_examples.batch(1024):
pt_tokens = tokenizers.pt.tokenize(pt_examples)
lengths.append(pt_tokens.row_lengths())
en_tokens = tokenizers.en.tokenize(en_examples)
lengths.append(en_tokens.row_lengths())
print('.', end='', flush=True)
print()
all_lengths = numpy.concatenate(lengths)
pyplot.hist(all_lengths, numpy.linspace(0, 500, 101))
pyplot.ylim(pyplot.ylim())
max_length = max(all_lengths)
pyplot.plot([max_length, max_length], pyplot.ylim())
pyplot.title(f'Maximum tokens per examples: {max_length}')
pyplot.show()7.4.3.3 使用 tf.data
以下函数将批量数据作为输入,并将其转换为适合训练的格式:
将它们进行标记化;
最大长度不超过
MAX_TOKENS;将目标拆分为输入和标签。这些标记回移动一步,这样每个输入位置的标签是下一个预测的标记;
将
RaggedTensor转换为填充的密集Tensor。- 返回
(inputs, labels)文本对。
def prepare_batch(pt, en):
pt = tokenizers.pt.tokenize(pt) # output is ragged
pt = pt[:, :MAX_TOKENS] # trim to MAX_TOKENS
pt = pt.to_tensor() # convert to 0-padded dense tensor
en = tokenizers.en.tokenize(en)
en = en[:, :(MAX_TOKENS + 1)]
en_inputs = en[:, :-1].to_tensor() # drop the [END] tokens
en_labels = en[:, 1:].to_tensor() # drop the [START] tokens
return (pt, en_inputs), en_labels下面的函数将文本数据集转换为批量数据,以供训练:
将文本进行标记,并过滤掉太长的句子。(使用
batch函数是因为在批量数据上进行标记更有效率;shuffle方法对批量数据进行随机排序;prefetch将数据集与模型并行运行,以确保在需要时有数据可用。
BUFFER_SIZE = 20000
BATCH_SIZE = 64
def make_batches(ds):
return (ds.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).map(
prepare_batch, tf.data.AUTOTUNE).prefetch(buffer_size=tf.data.AUTOTUNE))7.4.4 测试数据集
# Create training and validation set batches.
train_batches = make_batches(train_examples)
val_batches = make_batches(val_examples)
生成的 tf.data.Dataset 对象可以使用 Keras 进行训练。Keras 的 Model.fit 函数期望 (inputs, labels) 数据对。inputs 是葡萄牙语和西班牙语标记对 (pt, en) 。 labels 是相同的英语序列,移动 1 个单位。这个移动会导致每个位置输入的 en 序列,它的 label 是下一个标记,如下图所示:
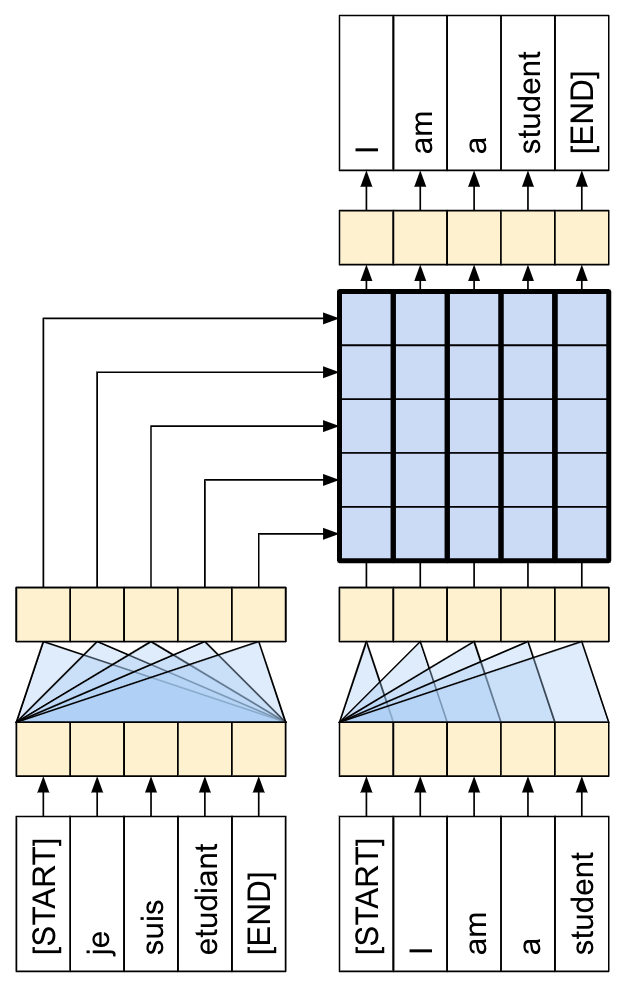
这种设置称为 Teacher Forcing ,因为无论模型在每个时间步的输出如何,它都会获得真实值作为下一个时间步的输入。这是一种简单而有效的文本生成模型训练方法。它之所以高效,是因为我们不需要按顺序运行模型,不同序列位置的输出可以并行计算。
你可能期望 (input, output) 简单地对应 (Portuguese, English) 句子。给定葡萄牙句子序列,模型会尝试生成英语序列。
可以使用这种方式训练模型。你需要写推理循环,将模型的输出传入到输入中。这种方式速度较慢(时间步骤不能并行运行),学习难度也较大(模型无法正确的出句子的结尾,除非它能正确得出句子的开头),但它可以提供更稳定的模型,因为模型必须在训练期间学会纠正自己的错误。
for (pt, en), en_labels in train_batches.take(1):
break
print(pt.shape)
print(en.shape)
print(en_labels.shape)
print(en[0][:10])
print(en_labels[0][:10])en 和 em_labels 是相同的,只是移动了一位:
(64, 64) (64, 59) (64, 59) tf.Tensor([ 2 76 144 162 317 77 5461 72 155 395], shape=(10,), dtype=int64) tf.Tensor([ 76 144 162 317 77 5461 72 155 395 13], shape=(10,), dtype=int64)
7.4.5 定义组件
Transformer 内部有很多内容。需要记住的重要事项是:
-
它遵循与带有编码器和解码器的标准序列到序列模型相同的一般模式;
-
如果我们一步一步地努力,一切都会变得有意义。
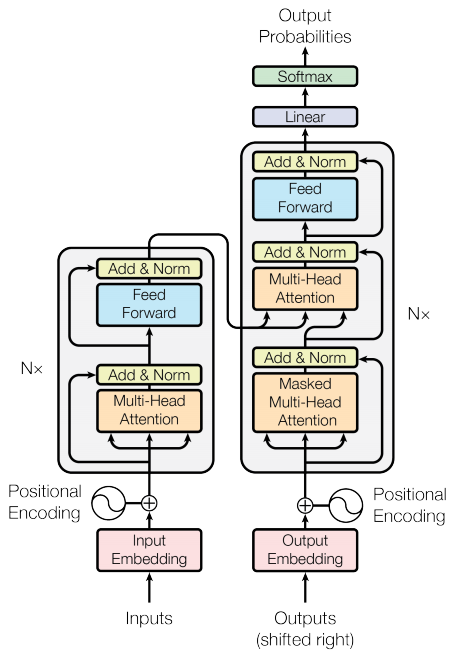
下图是 4 层的 Transformer 表示,我们将逐步解释其中每个组件,
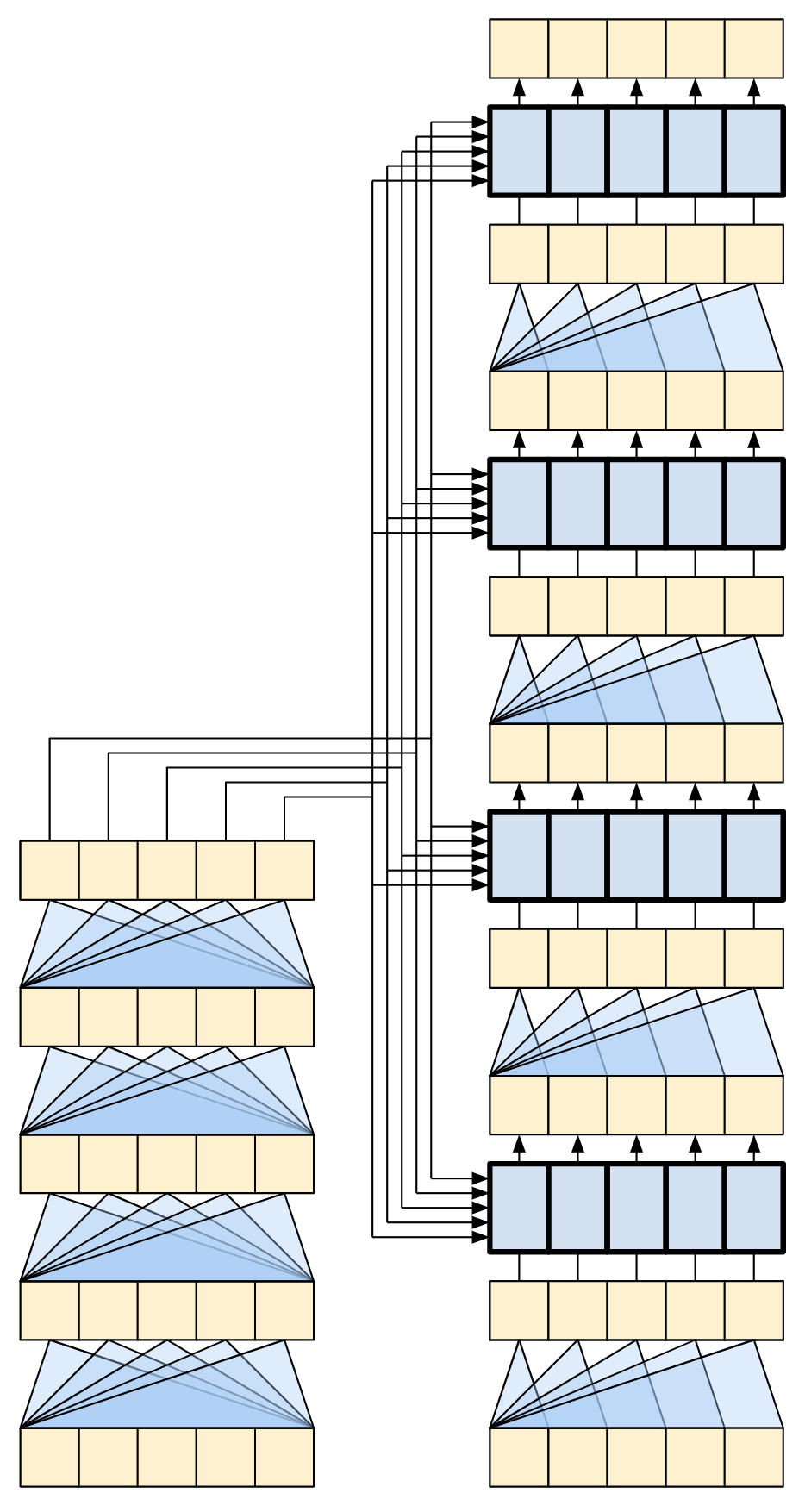
7.4.5.1 嵌入和位置编码
编码器和解码器的输入使用相同的嵌入和位置编码逻辑:
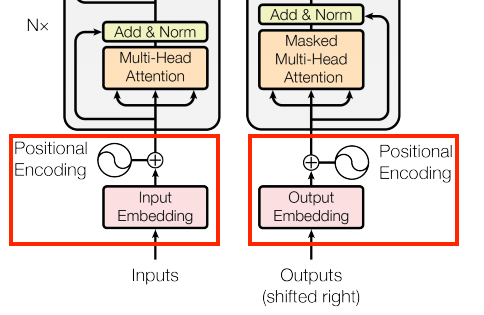
给定一个标记序列,输入标记(葡萄牙语)和目标标记(英语)都必须使用一个层转换为 keras.layers.Embedding 向量。
整个模型中使用的注意力层将其输入视为一组无序的向量。由于模型不包含任何循环层或者卷积层。它需要某种方法来识别词序,否则它会将输入序列视为一个词语背包,例如 how are you ,how you are 和 you how are ,它是无法区分的。
Transformer 为嵌入向量添加了 位置编码 (Positional Encoding) 。它使用一组不同频率的正弦和余弦(跨序列)。根据定义,附近的元素将具有相似的位置编码。
原始论文采用以下公式来计算位置编码:
\(PE_{(pos, 2i)} = sin(pos/10000^{2i/d_{model}})\)
\(PE_{(pos, 2i+1)} = cos(pos/10000^{2i/d_{model}})\)
下面的代码实现了它,但不是交错的正弦和余弦,而是简单地连接正弦和余弦向量。在功能上是等效的,而且更容易实现,并在下面的图中显示。
def positional_encoding(length, depth):
depth = depth / 2
positions = numpy.arange(length)[:, numpy.newaxis] # (seq, 1)
depths = numpy.arange(depth)[numpy.newaxis, :] / depth # (1, depth)
angle_rates = 1 / (10000**depths) # (1, depth)
angle_rads = positions * angle_rates # (pos, depth)
pos_encoding = numpy.concatenate(
[numpy.sin(angle_rads), numpy.cos(angle_rads)],
axis=-1)
return tf.cast(pos_encoding, dtype=tf.float32)位置编码函数是一堆正弦和余弦,它们根据沿嵌入向量,根据不同的位置深度,以不同的频率振动。
pos_encoding = positional_encoding(length=2048, depth=512)
# Check the shape.
print(pos_encoding.shape)
# Plot the dimensions.
pyplot.pcolormesh(pos_encoding.numpy().T, cmap='RdBu')
pyplot.ylabel('Depth')
pyplot.xlabel('Position')
pyplot.colorbar()
pyplot.show()使用它来创建一个 PositionEmbedding 层,查找嵌入向量的标记,将它和位置向量进行相加:
class PositionalEmbedding(keras.layers.Layer):
def __init__(self, vocab_size, d_model):
super().__init__()
self.d_model = d_model
self.embedding = keras.layers.Embedding(vocab_size, d_model, mask_zero=True)
self.pos_encoding = positional_encoding(length=2048, depth=d_model)
def compute_mask(self, *args, **kwargs):
return self.embedding.compute_mask(*args, **kwargs)
def call(self, x):
length = tf.shape(x)[1]
x = self.embedding(x)
# This factor sets the relative savel of the embedding and position_encoding.
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x = x + self.pos_encoding[tf.newaxis, :length, :]
return x注:原始论文中对源语言和目标语言都使用单个标记器和权重矩阵。本教程使用两个单独的标记器和权重矩阵。
embed_pt = PositionalEmbedding(vocab_size=tokenizers.pt.get_vocab_size().numpy(), d_model=512)
embed_en = PositionalEmbedding(vocab_size=tokenizers.en.get_vocab_size().numpy(), d_model=512)
pt_emb = embed_pt(pt)
en_emb = embed_en(en)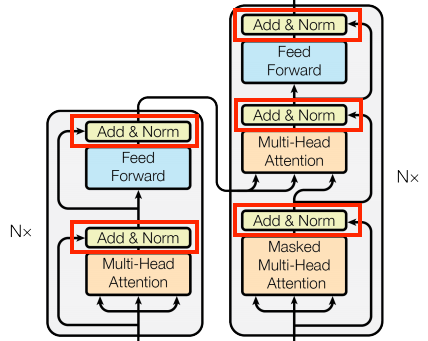
7.4.5.2 相加并规范化
这些 "Add & Norm" 块分散在整个模型中,每个块都加入一个残差连接,通过 LayerNormalization 进行归一化:
包含残差块可以提升训练效率,残差连接为梯度提供了直接路径(并确保向量由注意层更新而不是替换),而规范化则为输出保持合理的比例。
下面的实现,使用 Add 层确保 Keras 掩码可以被传播( + 符号不会)。
7.4.5.3 基础注意力层
整个模型都使用了注意力层,除了注意力的配置方式外,它们都是相同的。每个层都包含一个 layers.MultiHeadAttention 、一个 layers.LayerNormalization 和一个 layers.Add 。
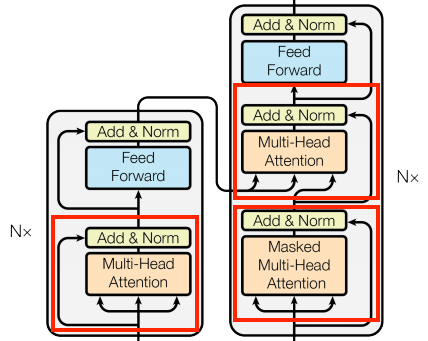
要实现这些注意层,请从仅包含组件层的简单基类开始。每个用例都将作为子类实现。这样编写的代码会多一点,但意图却很明确:
class BaseAttention(keras.layers.Layer):
def __init__(self, **kwargs):
super().__init__()
self.mha = keras.layers.MultiHeadAttention(**kwargs)
self.layernorm = keras.layers.LayerNormalization()
self.add = keras.layers.Add()在了解每种用法的具体细节之前,先快速回顾一下注意力的工作原理:
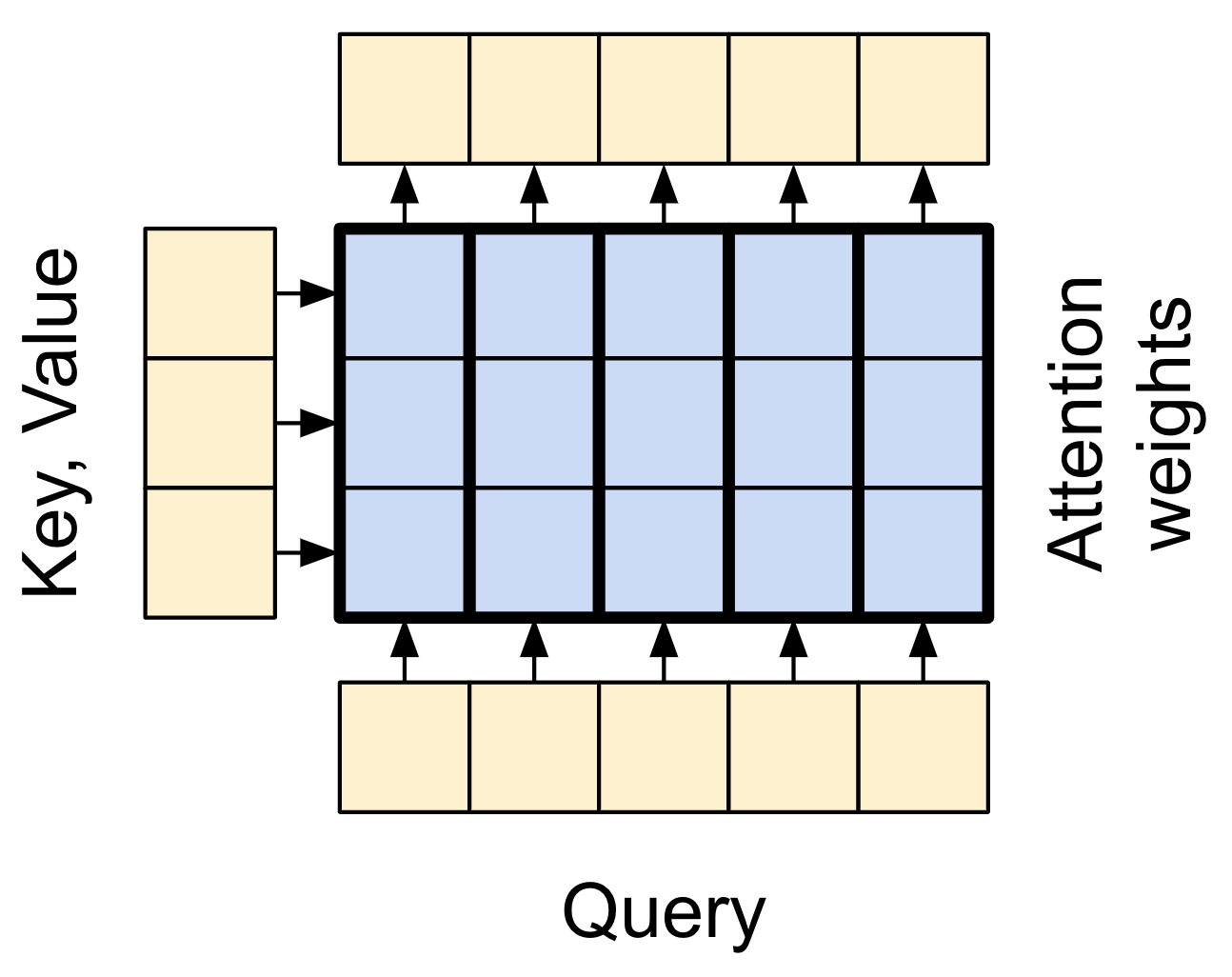
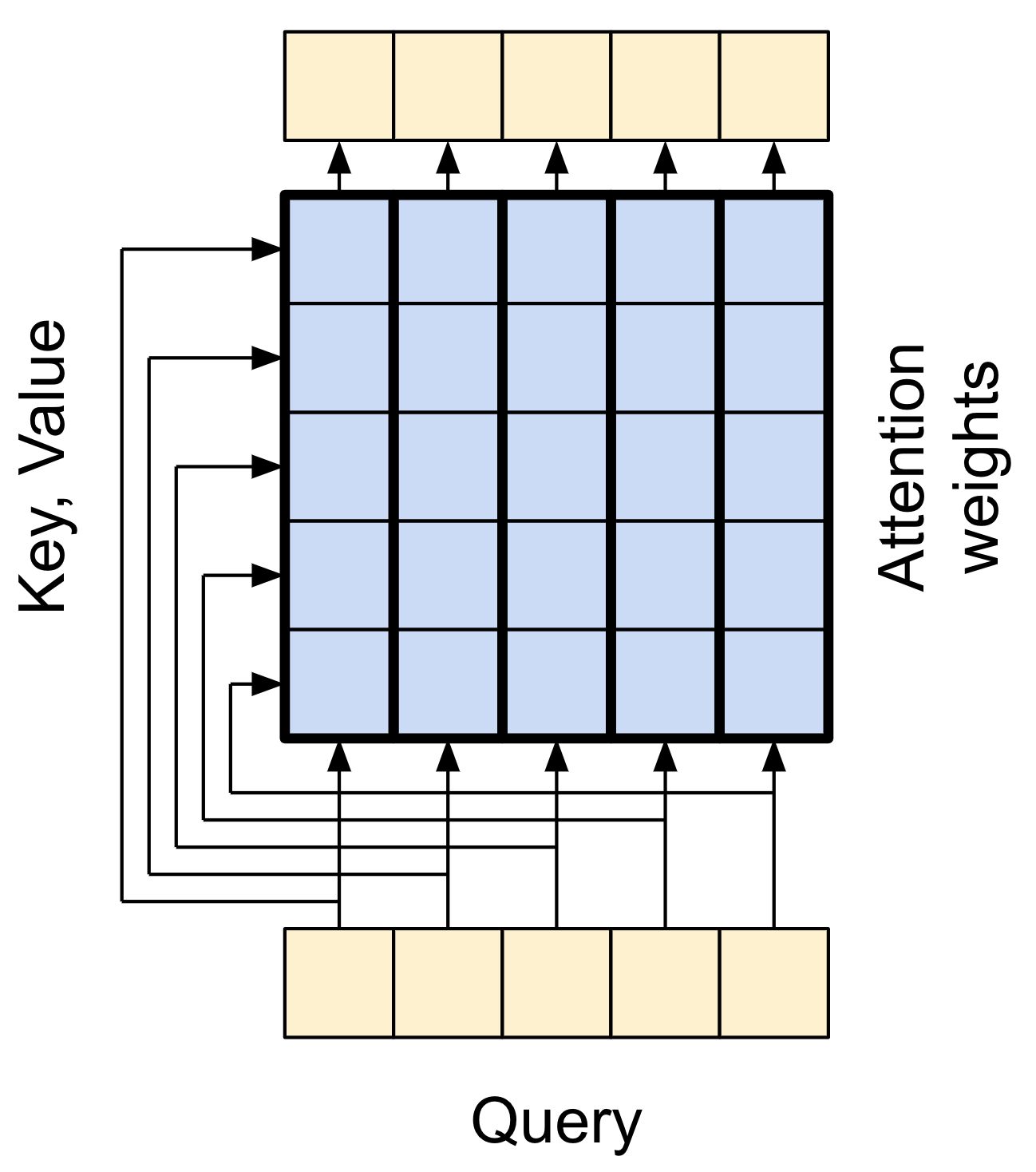
有两个输入:
查询 (Query) 序列(底部);
上下文序列(左边)。
输出和查询序列有相同的维度,可以将此操作与模糊的、可微的、矢量化的字典查找做比较,下面是一个常规的 Python 字典,其中有 3 个键和 3 个值,通过单个查询传递:
d = {'color': 'blue', 'age': 22, 'type': 'pickup'}
result = d['color']
print(result)query 就是我们正在寻找的;
key 就是字典里信息的类型;
value就是实际的信息。
当你在一个字典中想要查询 query 时,字典发现对应的 key ,并返回和它相关联的 value 。query 可能有,也可能没有对应的 key 。你可以将它想象成为一个模糊的字典,其中的 key 并不完全匹配。如果你在上面字典里查找 d["species"] ,它可能会返回 "pickup" ,因为那就是查询的最佳匹配。
注意力层灰进行这样的模糊查找,但它不只是寻找最佳键。它会根据 query 和每个 key 的匹配程度,将 values 进行组合。
它是如何工作的?在注意层中 query 、 key 和 value 都是向量。注意层不会进行哈希查找,而是将 query 和 key 向量组合起来确定它们的匹配程度,即 注意分数 (Attention Score) 。该层返回所有 values的平均值,由注意力的粉进行加权。
查询序列的每个位置都提供一个 query 向量。上下文序列充当字典,他的每个位置都提供一个 key 和 value 向量。
并不直接使用输入向量,在使用之前,layers.MultiHeadAttention 包含一个 layers.Dense 层将输入向量进行 投影 (Project) 。
7.4.5.4 交叉注意力层
Transformer 的核心是交叉注意力层, 该层连接编码器和解码器。该层是模型中最直接使用注意力的层,它执行的任务与 第 7.3 小节 Seq2Seq 翻译 中的注意力模块相同。
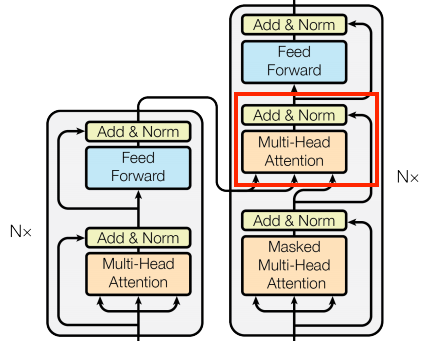
为了实现这一点,当调用 mha 层时,你将目标序列 x 作为 query ,context 序列作为 key/value 。
class CrossAttention(BaseAttention):
def call(self, x, context):
attn_output, attn_scores = self.mha(query=x,
key=context,
value=context,
return_attention_scores=True)
# Cache the attention scores for plotting later.
self.last_attn_scores = attn_scores
x = self.add([x, attn_output])
x = self.layernorm(x)
return xsample_ca = CrossAttention(num_heads=2, key_dim=512)
print(pt_emb.shape)
print(en_emb.shape)
print(sample_ca(en_emb, pt_emb).shape)(64, 64, 512) (64, 59, 512) (64, 59, 512)
7.4.5.5 全局自注意力层
该层负责处理上下文信息,并在其中传递信息:
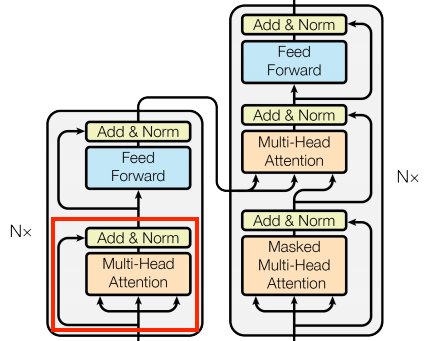
由于在生成翻译时上下文序列时固定的,因此信息可以双向流。在 Transformer 和自注意力之前,模型通常使用 RNN 或 CNN 来完成这项任务,下图分别显示 RNN 和 CNN :
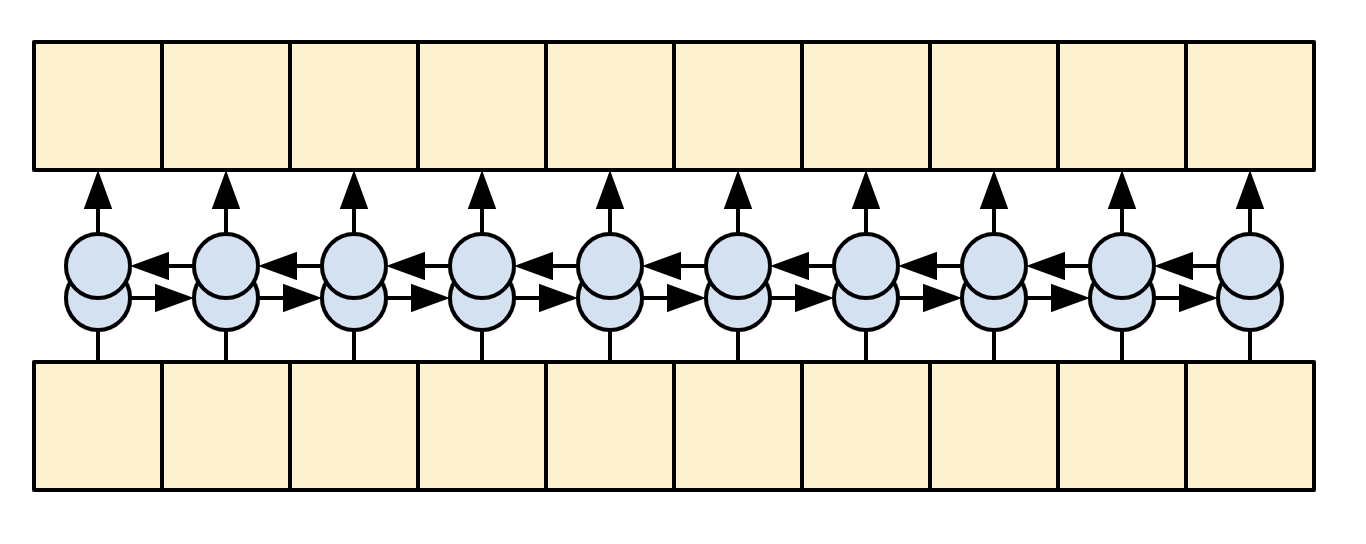
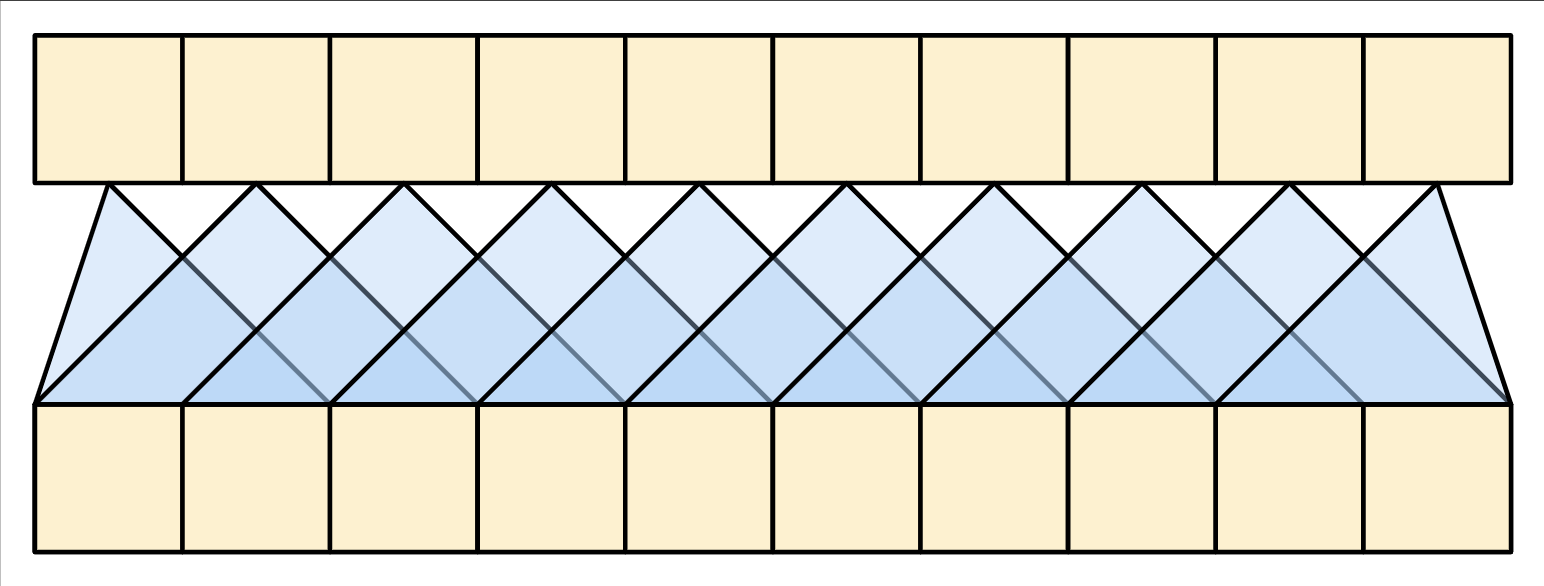
RNN 和 CNN 都有其局限性:
-
RNN 允许信息在整个序列中流动,但它需要经过许多处理步骤才能到达那里。这些 RNN 步骤必须按顺序执行,因此 RNN 不太能够利用现代并行设备。
-
在 CNN 中,每个位置都可以并行处理,但它仅提供有限的接受场。接受场仅随 CNN 层数线性增长,你需要堆叠多个卷积层才能在序列中传递信息。
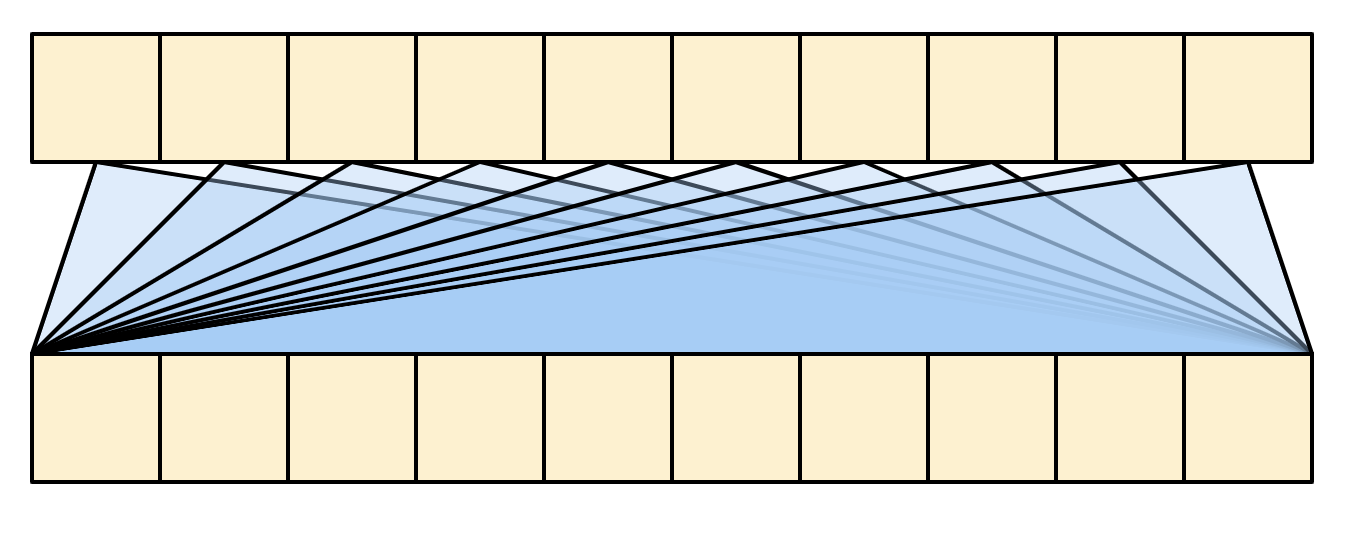
另一方面,全局自注意力允许每个元素直接访问每个其它序列元素,只需少量操作,并且所有输出都可以并行计算。
要实现这一层,我们只需要将目标序列 x 作为 query 和 value 传递给 mha 层:
sample_gsa = GlobalSelfAttention(num_heads=2, key_dim=512)
print('> Global self attention:')
print(pt_emb.shape)
print(sample_gsa(pt_emb).shape)(64, 64, 512) (64, 64, 512)
我们可以像下图这样绘制:
为了简单期间,残差层被忽略。下图绘制更加紧凑,并且同样精确:
7.4.5.6 因果自注意力层
对于输出序列,该层的作用与全局自注意力层类似:
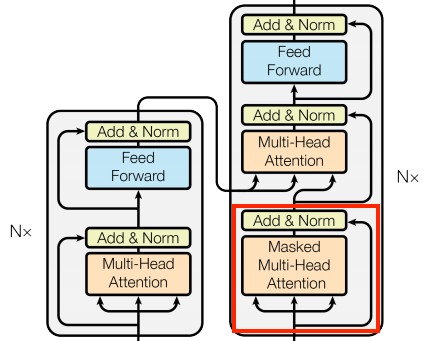
Transformer 是一种自回归模型:它们一次生成一个标记文本,并将该输出反馈给输入。为了提高效率,这些模型确保每个序列元素的输出仅取决于前一个序列元素。