2.6 Optimizer
Created Date: 2025-06-23
There are many optimizers available for machine learning and deep learning, with the exact number being difficult to pinpoint as new ones are constantly being developed and existing ones are adapted. However, some popular and well-established optimizers include Gradient Descent (and its variations like Stochastic Gradient Descent and Mini-batch Gradient Descent), Adagrad, RMSprop, Adam, and Adadelta. The choice of optimizer often depends on the specific problem, dataset size, and desired convergence speed.
The image visually explains how an optimizer works by iteratively adjusting a parameter (w) from a random starting point to find the value that minimizes the loss function.
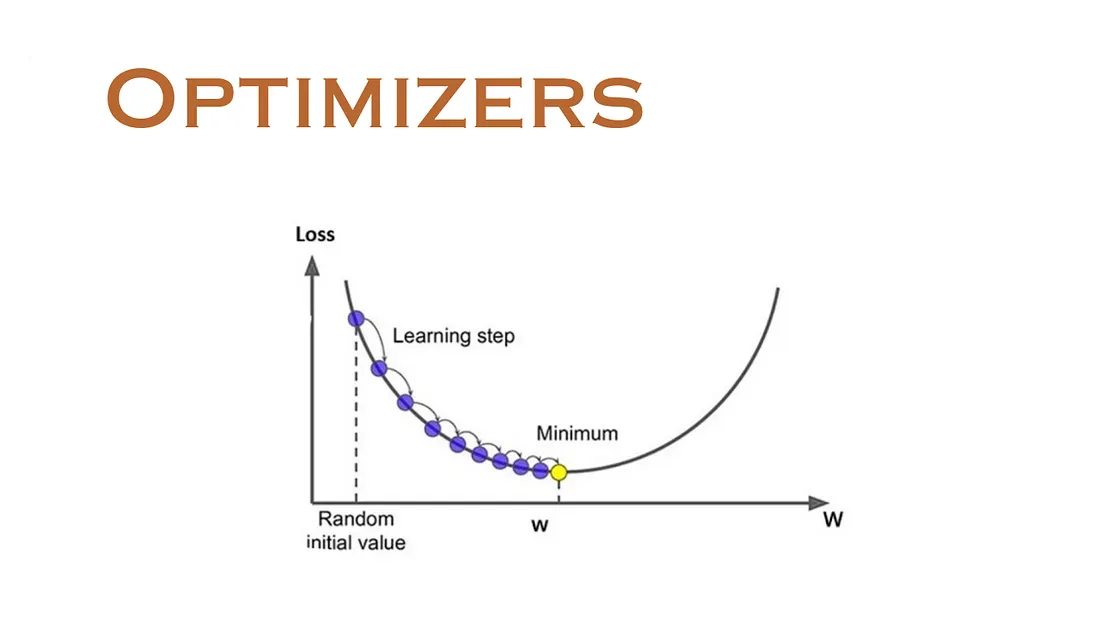
Figure 1 - Optimizer
We can set a constant learning rate of 0.001, or adjust the learning rate during training, which leads to different types of optimizers.
Here's a breakdown of some key optimizer categories and examples:
1. Gradient Descent Based Optimizers
Gradient Descent: The foundational optimizer that iteratively adjusts model parameters to minimize a loss function by moving in the direction of the steepest descent of the gradient.
Stochastic Gradient Descent (SGD): Updates parameters using the gradient calculated on a single randomly selected data point (or a mini-batch). This is generally faster than vanilla gradient descent for large datasets.
Mini-batch Gradient Descent: A variation of SGD that uses a small batch of data points for gradient calculation, offering a balance between speed and stability.
2. Adaptive Learning Rate Optimizers
Adagrad: Adapts the learning rate for each parameter based on the historical sum of squared gradients.
RMSprop: Divides the learning rate by a moving average of the past squared gradients, making it suitable for non-convex problems.
Adam: Combines the benefits of RMSprop and momentum by using exponentially decaying averages of past gradients and past squared gradients. It's often a good starting point for many deep learning tasks.
3. Other Notable Optimizers
Adadelta: An extension of Adagrad that addresses its diminishing learning rate issue by using a moving average of past updates.
AdamW: A variant of Adam that decouples weight decay from the learning rate update, often leading to better generalization.
Lion: A recently developed optimizer that addresses some limitations of Adam and is gaining traction.
The best optimizer for a specific task is often determined through experimentation and by considering factors like the dataset size, the complexity of the model, and the desired convergence speed.
2.6.1 Basic Usage
To use torch.optim you have to construct an optimizer object that will hold the current state and will update the parameters based on the computed gradients.
To construct an Optimizer you have to give it an iterable containing the parameters (all should be Parameter s) or named parameters (tuples of (str, Parameter)) to optimize. Then, you can specify optimizer-specific options such as the learning rate, weight decay, etc. Example:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = torch.optim.Adam([var1, var2], lr=0.0001)All optimizers implement a step() method, that updates the parameters. It can be used in two ways:
optimizer.step()This is a simplified version supported by most optimizers. The function can be called once the gradients are computed using e.g. backward() .
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()Some optimization algorithms such as Conjugate Gradient and LBFGS need to reevaluate the function multiple times, so you have to pass in a closure that allows them to recompute your model. The closure should clear the gradients, compute the loss, and return it:
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)2.6.2 Stochastic Gradient Descent (SGD)
Stochastic Gradient Descent (SGD) is an optimization algorithm used to minimize a loss function by updating the model’s parameters \(\theta\) in the direction of the negative gradient. It is a stochastic (randomized) version of standard gradient descent that updates parameters using only one data point at a time, rather than the entire dataset.
The simple update rule is:
where \(\eta\) is the learning rate, \(\nabla_\theta L_i(\theta)\) is the gradient of the loss function \(L\) with respect to the parameters \(\theta\) for the \(i\)-th data point.
File simple_sgd.py show a simple example:
# training data
x = 1
y = 2
w = 0
learning_rate = 0.1
y_pred = w * x
loss = (y_pred - y) ** 2
dw = 2 * (w * x - y) * x
w = w - learning_rate * dw
print(f'Initial w: 0, learning_rate: {learning_rate}')
print(f'After training: w: {w}, gradient dw: {dw}')Initial w: 0, learning_rate: 0.1 After training: w: 0.4, gradient dw: -4
In this single step, \(w\) moved from 0 to 0.4.
In PyTorch, you can use the torch.optim.SGD class to implement SGD.
# implementation with torch
x = torch.tensor(1.0)
y = torch.tensor(2.0)
# weight parameter with gradient tracking
w_torch = torch.tensor(0.0, requires_grad=True)
# define optimizer
optimizer = torch.optim.SGD([w_torch], lr=0.1)
# forward pass
y_pred = w_torch * x
loss = (y_pred - y) ** 2
# backward pass
loss.backward()
optimizer.step()
assert torch.isclose(w_torch, torch.tensor(w), atol=1e-6)PyTorch class torch.optim.SGD Implements stochastic gradient descent (optionally with momentum).
torch.optim.SGD(params, lr=0.001, momentum=0, dampening=0, weight_decay=0,
nesterov=False, *, maximize=False, foreach=None, differentiable=False, fused=None)Nesterov momentum is based on the formula from On the importance of initialization and momentum in deep learning .
Imagine you're still rolling a ball down the hilly landscape, but now the ball has momentum. If it's been rolling in a certain direction for a while, it gains speed and tends to continue in that direction, even if there's a small uphill slope or a flat region. This helps it overcome small obstacles and accelerate through consistent gradients.
File sgd_momentum.py Demonstrate how SGD (Stochastic Gradient Descent) with momentum can "jump over" a local minimum, where SGD without momentum might get stuck:
for i in range(num_iterations):
# Optimization step for SGD with Momentum
optimizer_momentum.zero_grad() # Clear previous gradients
loss_m = model_momentum() # Compute loss
loss_m.backward() # Backpropagate to compute gradients
optimizer_momentum.step() # Update parameters
history_momentum_x.append(model_momentum.x.item())
history_momentum_loss.append(loss_m.item())
# Optimization step for SGD without Momentum
optimizer_nomomentum.zero_grad()
loss_nm = model_nomomentum()
loss_nm.backward()
optimizer_nomomentum.step()
history_nomomentum_x.append(model_nomomentum.x.item())
history_nomomentum_loss.append(loss_nm.item())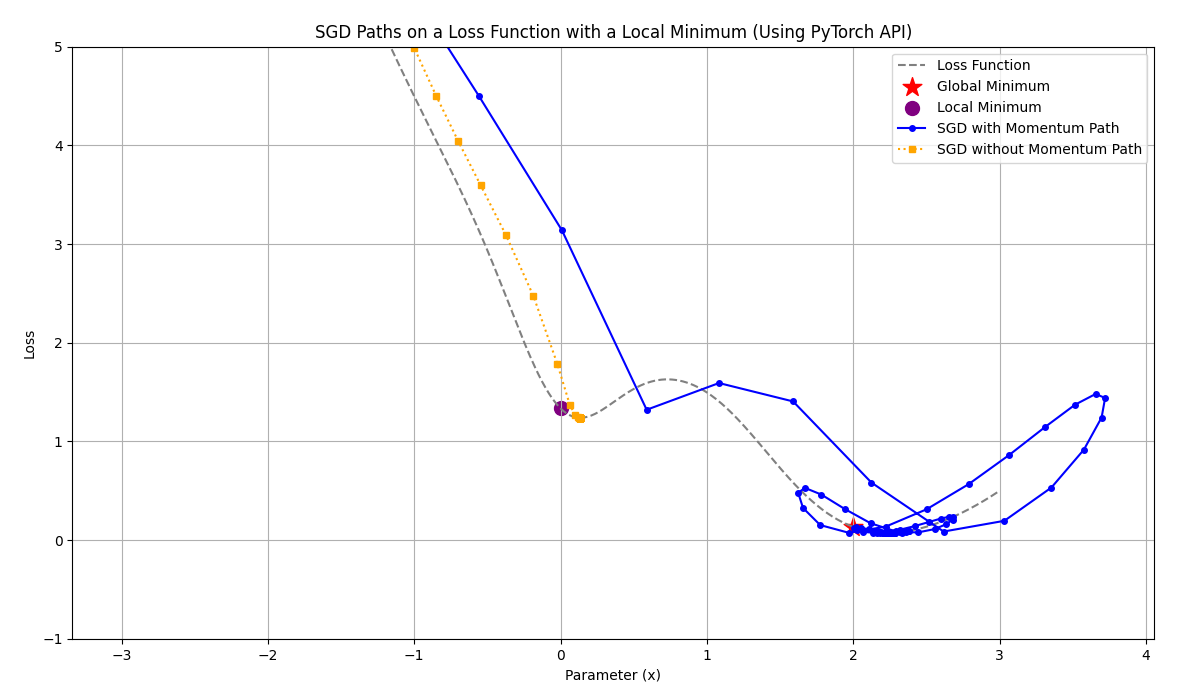
Figure 2 - SGD Momentum
In the figure, the gray line represents the Loss Landscape, showing how the loss changes with different values of \(x\). The blue line represents the path taken by SGD with momentum, while the yellow line shows the path taken by SGD without momentum. The brown dot indicates the local minimum that SGD without momentum gets stuck in, while the red pentagram shows how SGD with momentum can jump over this local minimum and continue to find a better solution.
2.6.3 Adam
We (Diederik P. Kingma, Jimmy Ba) propose Adam , a method for efficient stochastic optimization that only requires first-order gradients with little memory requirement. The method computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients; the name Adam is derived from adaptive moment estimation.
Algorithm: Adam, our proposed algorithm for stochastic optimization, and for a slightly more efficient (but less clear) order of computation. \(g_t^2\) indicates the elementwise square \(g_t \odot g_t\). Good default settings for the tested machine learning problem are \(\alpha = 0.001\), \(\beta_1 = 0.9\), \(\beta_2 = 0.999\) and \(\epsilon = 10^{-8}\). All operations on vectors are element-wise. With \(\beta_1^t\) and \(\beta_2^t\) we denote \(\beta_1\) and \(\beta_2\) to the power \(t\).
\(\alpha\): StepSize;
\(\beta_1, \beta_2 \in [0, 1)\): Exponential decay rates for the moment estimates;
\(f(\theta)\): Stochastic objective function with parameters \(\theta\) ;
\(\theta_0\): Initial parameter vector;
\(m_0 \leftarrow 0\): (Initialize \(1^{st}\) moment vector);
\(v_0 \leftarrow 0\): (Initialize \(2^{nd}\) moment vector);
\(t \leftarrow 0\): (Initialize timestep).
File simple_adam.py implements a simplified version of the Adam optimizer in PyTorch to minimize the function \(f(x) = {(x - 3)}^2\). It tracks and plots the optimization process, showing how \(x\) converges towrad 3 and the loss decreases over 150 steps:
class SimpleAdam:
def __init__(self, params, lr=0.1, betas=(0.9, 0.999), eps=1e-8):
self.params = list(params)
self.lr = lr
self.beta1, self.beta2 = betas
self.eps = eps
self.m = [torch.zeros_like(p) for p in self.params]
self.v = [torch.zeros_like(p) for p in self.params]
self.t = 0
def step(self):
self.t += 1
for i, p in enumerate(self.params):
if p.grad is None:
continue
g = p.grad.data
self.m[i] = self.beta1 * self.m[i] + (1 - self.beta1) * g
self.v[i] = self.beta2 * self.v[i] + (1 - self.beta2) * (g**2)
m_hat = self.m[i] / (1 - self.beta1**self.t)
v_hat = self.v[i] / (1 - self.beta2**self.t)
p.data -= self.lr * m_hat / (v_hat.sqrt() + self.eps)
def zero_grad(self):
for p in self.params:
if p.grad is not None:
p.grad.zero_()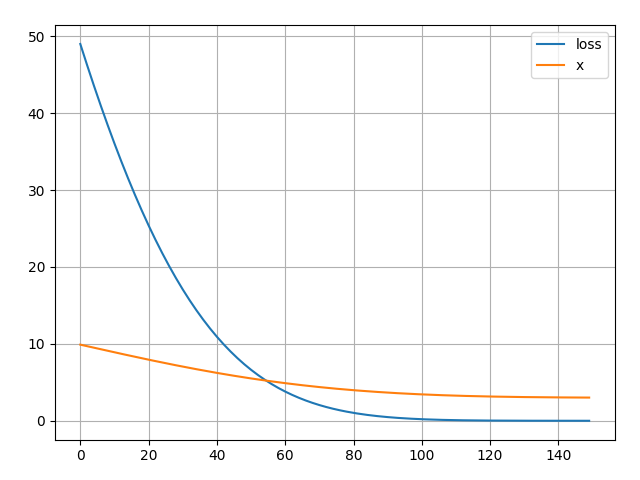
Figure 2 - Simple Adam
Step 010 | x = 9.00517 | loss = 37.25632 Step 020 | x = 8.04014 | loss = 26.36289 Step 030 | x = 7.13265 | loss = 17.80930 Step 040 | x = 6.30562 | loss = 11.45278 Step 050 | x = 5.57491 | loss = 6.98728 Step 060 | x = 4.94909 | loss = 4.02744 Step 070 | x = 4.43005 | loss = 2.18219 Step 080 | x = 4.01389 | loss = 1.10479 Step 090 | x = 3.69198 | loss = 0.51877 Step 100 | x = 3.45239 | loss = 0.22376 Step 110 | x = 3.28132 | loss = 0.08747 Step 120 | x = 3.16465 | loss = 0.03037 Step 130 | x = 3.08909 | loss = 0.00905 Step 140 | x = 3.04303 | loss = 0.00217 Step 150 | x = 3.01703 | loss = 0.00036 Adam.Scratch Final x: 3.01703, Final Loss: 0.00029
We can use torch.optim.Adam implement above training process:
# Another implementation with torch.optim.Adam
x_torch_adam = torch.tensor([10.0], requires_grad=True)
optimizer_torch_adam = torch.optim.Adam([x_torch_adam], lr=0.1)
losses_torch_adam = []
xs_torch_adam = []
for step in range(150):
optimizer_torch_adam.zero_grad() # Same zero_grad call
loss = (x_torch_adam - 3) ** 2
loss.backward() # Same backward call
optimizer_torch_adam.step() # Same step callStep 050 | x = 5.57491 | loss = 6.98728 Step 100 | x = 3.45239 | loss = 0.22375 Step 150 | x = 3.01703 | loss = 0.00036 Torch.Adam Final x: 3.01703, Final Loss: 0.00029
2.6.4 lr_scheduler
torch.optim.LRScheduler Adjusts the learning rate during optimization.
torch.optim.lr_scheduler.LRScheduler(optimizer, last_epoch=-1)File simple_lr_scheduler.py defines a CustomSchedule :
class CustomSchedule(torch.optim.lr_scheduler._LRScheduler):
"""
Implements the learning rate schedule described in the Transformer paper.
lr = d_model^(-0.5) * min(step^(-0.5), step * warmup_steps^(-1.5))
"""
def __init__(
self, optimizer, d_model: int, warmup_steps: int = 4000
): # Added type hints
self.d_model = float(d_model) # Cast to float immediately
self.warmup_steps = float(warmup_steps) # Cast to float
# Call super().__init__ after all self attributes are set if they are used in get_lr
super().__init__(optimizer)
def get_lr(self):
# self.last_epoch stores the current step/epoch count (0-indexed)
# We need to add 1 because step is typically 1-indexed in LR schedules.
step = self.last_epoch + 1
step_f = float(step) # Ensure step is float for calculations
# Handle the case where step is 0 to avoid division by zero in rsqrt(0)
# For the original formula, step should start from 1.
# If last_epoch starts at -1 (default for _LRScheduler), step will be 0 on first call.
# For Transformer's LR, step=0 means LR=0.
if step_f == 0:
return [0.0] * len(self.optimizer.param_groups)
# Calculate arg1 and arg2
arg1 = torch.rsqrt(torch.tensor(step_f))
arg2 = torch.tensor(step_f) * (self.warmup_steps**-1.5)
# Calculate the final learning rate
lr = torch.rsqrt(torch.tensor(self.d_model)) * torch.min(arg1, arg2)
# Return a list of learning rates, one for each parameter group
# Since this schedule computes a single LR, we apply it to all groups.
return [lr.item()] * len(self.optimizer.param_groups)Define a model:
# --- Training Setup ---
# 1. Define your model
model = torch.nn.Linear(10, 1) # Still a simple linear model
# 2. Define your optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.98), eps=1e-9)
# 3. Define your loss function
criterion = torch.nn.MSELoss()
# 4. Instantiate the custom learning rate schedule
d_model = 512
warmup_steps = 4000
scheduler = CustomSchedule(optimizer, d_model, warmup_steps)