7.3 Language Modeling
Created Date: 2025-06-19
7.3.1 Llama Quick Start
7.3.1.1 Install Required Libraries
pip3 install transformers accelerate sentencepiece
7.3.1.2 Choose a Model
model_name = 'NousResearch/Llama-2-7b-chat-hf'7.3.1.3 Load the Tokenizer and Model
How to estimate the model size:
The model has about 7 billion (7B) parameters.
Using 16-bit floating point precision means each parameter takes 2 bytes.
Calculate total size: 7,000,000,000 parameters × 2 bytes = 14,000,000,000 bytes ≈ 13 GB
If we use this model, we need to have a good network environment so that we don't spend too much time on downloading.
model.safetensors.index.json: 100%|███████████████████████████████████| 26.8k/26.8k
model-00002-of-00002.safetensors: 100%|███████████████████████████████████| 3.50G/3.50G
model-00001-of-00002.safetensors: 100%|███████████████████████████████████| 10.0G/10.0G
7.3.1.4 Build a Prompt
The LLaMA Chat models expect prompts wrapped in [INST] ... [/INST] tags:
prompt = "<s>[INST] Explain what a black hole is in one sentence. [/INST]"You can also include a system prompt for better alignment:
prompt = (
"<s>[INST] <<SYS>>\n"
"You are a helpful, intelligent assistant.\n"
"<</SYS>>\n"
"Explain what a black hole is in one sentence.\n[/INST]"
)
7.3.1.5 Generate Text
7.3.2 DeepSeek-V3
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance.
We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models.
Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks.
7.3.2.1 Architecture
We first introduce the basic architecture of DeepSeek-V3, featured by Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) for efficient inference and DeepSeekMoE (Dai et al., 2024) for economical training. Then, we present a Multi-Token Prediction (MTP) training objective, which we have observed to enhance the overall performance on evaluation benchmarks. For other minor details not explicitly mentioned, DeepSeek-V3 adheres to the settings of DeepSeek-V2 (DeepSeek-AI, 2024c).
Basic Architecture
The basic architecture of DeepSeek-V3 is still within the Transformer (Vaswani et al., 2017) framework. For efficient inference and economical training, DeepSeek-V3 also adopts MLA and DeepSeekMoE, which have been thoroughly validated by DeepSeek-V2.
Compared with DeepSeek-V2, an exception is that we additionally introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the performance degradation induced by the effort to ensure load balance. Figure 2 illustrates the basic architecture of DeepSeek-V3, and we will briefly review the details of MLA and DeepSeekMoE in this section.
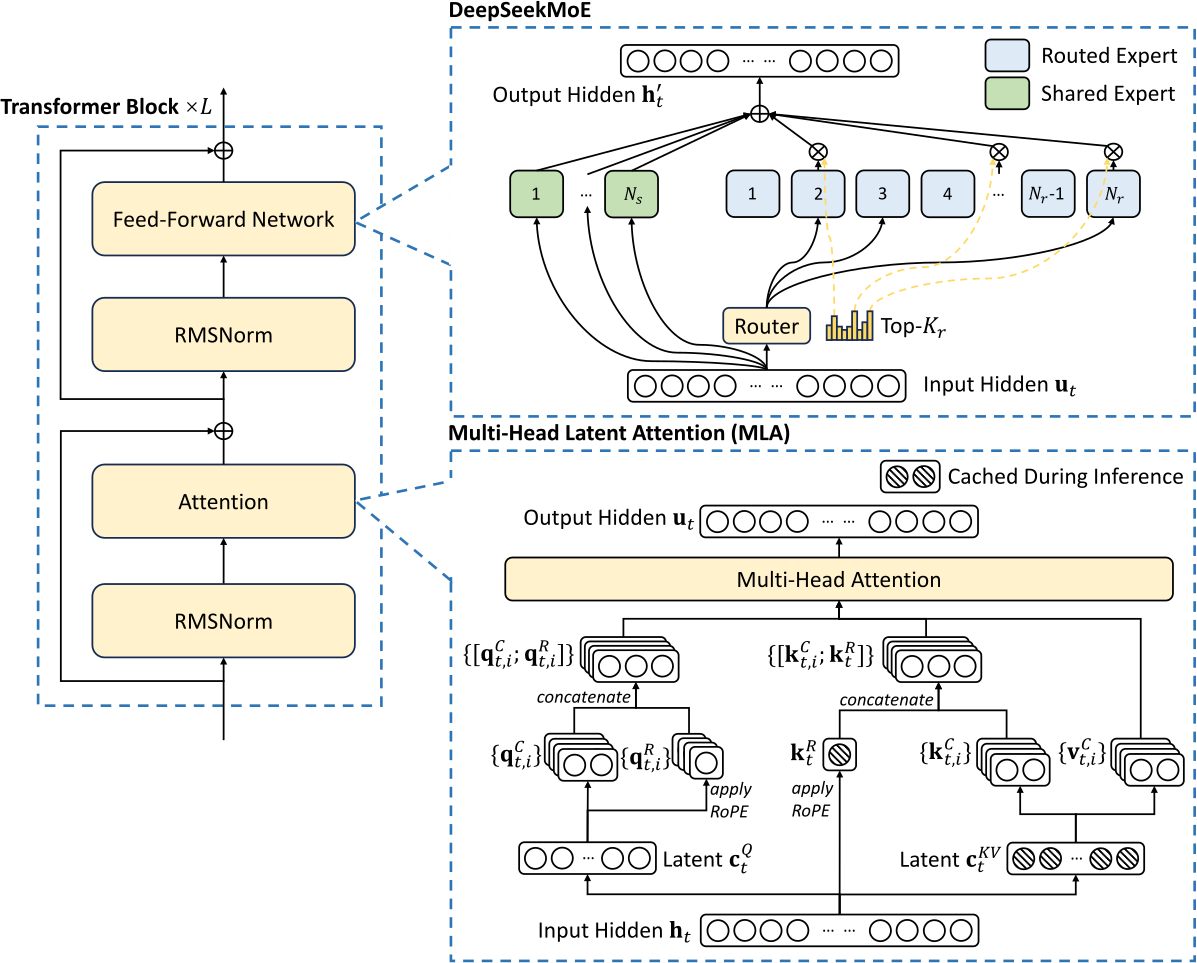
Figure 2 - Basic Architecture of DeepSeek-V3
Multi-Head Latent Attention
For attention, DeepSeek-V3 adopts the MLA architecture. Let \(d\) denote the embedding dimension, \(n_h\) denote the number of attention heads, \(d_h\) denote the dimension per head, and \(h_t \in \mathbb{R}^d\) denote the attention input for the 𝑡-th token at a given attention layer. The core of MLA is the low-rank joint compression for attention keys and values to reduce Key-Value (KV) cache during inference: