1.3 Data Representation
Created Date: 2025-05-01
The data you'll manipulate will almost always fall into one of the following categories:
Vector data - Rank-2 tensors of shape (samples, features), where each sample is a vector of numerical attributes ("features").
Timeseries data or sequence data - Rank-3 tensors of shape (samples, timesteps, features), where each sample is a sequence (of length timesteps) of feature vectors.
Images - Rank-4 tensors of shape (samples, height, width, channels), where each sample is a 2D grid of pixels, and each pixel is represented by a vector of values ("channels").
Video - Rank-5 tensors of shape (samples, frames, height, width, channels), where each sample is a sequence (of length frames) of images.
1.3.1 Features
The most simplest features is point, For example a point in a 2D space is defined by two coordinates, typically \((x, y)\):
point_sample = torch.tensor([0.5, 1])Here, point_sample represents a point with an x-coordinate of 0.5 and a y-coordinate of 1.
File features_1d.py uses the NumPy library to generate a dataset that simulate a linear relationship with added random noise.
rng = numpy.random.default_rng(seed=0)
random_numbers = rng.standard_normal(size=100)
x_input_array = numpy.linspace(0, 4, 100)
y_true_array = 3 * x_input_array + 4 + random_numbers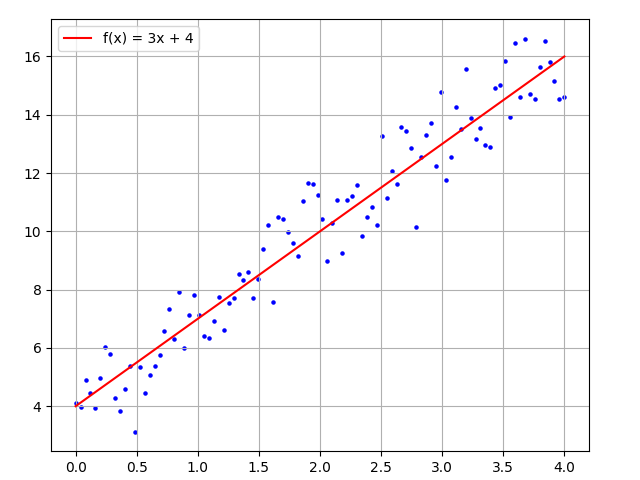
Figure 1 - Points Data
We can combines two separate lists of data (x_input_array and y_true_array) into a single, structure dataset called point_dataset. The key takeaway is that the resulting point_dataset is organized into a (samples, features) shape, which is a fundamental format for data in machine learning and data science.
point_dataset = numpy.stack((x_input_array, y_true_array), axis=-1)
assert point_dataset.shape == (100, 2)1.3.2 Text
Large Movie Review Dataset is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing.
File text_data.py downloads the Large Movie Review Dataset (aclImdb), a sentiment analysis benchmark, from a Stanford server. The script uses a sha1_hash to ensure the downloaded file's integrity. It then extracts the compressed data, organizing it into a folder structure with separate subdirectories for positive and negative reviews:
import sys
import pathlib
import os
import tarfile
project_root = pathlib.Path(__file__).resolve().parents[2]
sys.path.append(str(project_root))
from common import download
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
file_path = download.download(url, sha1_hash='01ada507287d82875905620988597833ad4e0903')
extract_dir = os.path.dirname(file_path)
os.makedirs(extract_dir, exist_ok=True)
with tarfile.open(file_path, 'r:gz') as tar:
tar.extractall(path=extract_dir)
extract_file_dir = os.path.join(extract_dir, 'aclImdb')
print('Successfully extracted to:', extract_file_dir)
train_dir = os.path.join(extract_file_dir, 'train')
print(os.listdir(train_dir))
train_pos_dir = os.path.join(extract_file_dir, 'train/pos')
train_neg_dir = os.path.join(extract_file_dir, 'train/neg')
print('Train positive dir:', train_pos_dir)
print('Train negative dir:', train_neg_dir)
train_pos_files = os.listdir(train_pos_dir)
train_neg_files = os.listdir(train_neg_dir)
examples_files = train_pos_files[:3]
for index, fname in enumerate(examples_files):
fpath = os.path.join(train_pos_dir, fname)
with open(fpath, 'r', encoding='utf-8') as f:
content = f.read()
print(str(index + 1) + ':', content)1: For a movie that gets no respect there sure are a lot of memorable quotes listed for this gem. Imagine a movie where Joe Piscopo is actually funny! Maureen Stapleton is a scene stealer. The Moroni character is an absolute scream. Watch for Alan "The Skipper" Hale jr. as a police Sgt. 2: Bizarre horror movie filled with famous faces but stolen by Cristina Raines (later of TV's "Flamingo Road") as a pretty but somewhat unstable model with a gummy smile who is slated to pay for her attempted suicides by guarding the Gateway to Hell! The scenes with Raines modeling are very well captured, the mood music is perfect, Deborah Raffin is charming as Cristina's pal, but when Raines moves into a creepy Brooklyn Heights brownstone (inhabited by a blind priest on the top floor), things really start cooking. The neighbors, including a fantastically wicked Burgess Meredith and kinky couple Sylvia Miles & Beverly D'Angelo, are a diabolical lot, and Eli Wallach is great fun as a wily police detective. The movie is nearly a cross-pollination of "Rosemary's Baby" and "The Exorcist"--but what a combination! Based on the best-seller by Jeffrey Konvitz, "The Sentinel" is entertainingly spooky, full of shocks brought off well by director Michael Winner, who mounts a thoughtfully downbeat ending with skill. ***1/2 from **** 3: A solid, if unremarkable film. Matthau, as Einstein, was wonderful. My favorite part, and the only thing that would make me go out of my way to see this again, was the wonderful scene with the physicists playing badmitton, I loved the sweaters and the conversation while they waited for Robbins to retrieve the birdie.
1.3.3 Audio
free-spoken-digit-dataset is a simple audio/speech dataset consisting of recordings of spoken digits in wav files at 8kHz. The recordings are trimmed so that they have near minimal silence at the beginnings and ends.
Files are named in the following format: {digitLabel}_{speakerName}_{index}.wav, Example: 7_jackson_32.wav.
Command python3 script/git_sync_deps.py will download the free-spoken-digit-dataset to data dir. File audio_data.py load these data, and use Matplotlib draw some of them:
import glob
import os
from matplotlib import pyplot
import soundfile
data_dir = 'data/free-spoken-digit-dataset/recordings'
wav_files = glob.glob(os.path.join(data_dir, '*.wav'))
samples = wav_files[:4]
fig, axs = pyplot.subplots(2, 2, figsize=(10, 6))
axs = axs.flatten()
for idx, f in enumerate(samples):
audio, sr = soundfile.read(f, dtype='float32')
axs[idx].plot(audio)
axs[idx].set_title(f"{os.path.basename(f)}")
pyplot.tight_layout()
pyplot.show()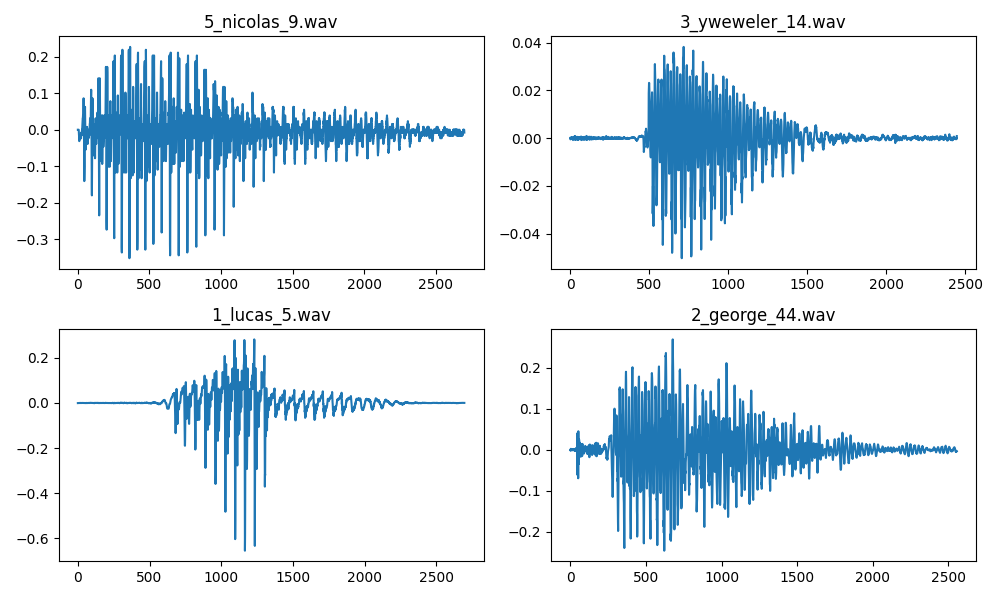
Figure 2 - Audio Samples
1.3.4 Image
The MNIST database contains 60,000 training samples and 10,000 test samples of size-normalized handwritten digits. This database was derived from the original NIST databases.
MNIST is widely used by researchers as a benchmark for testing pattern recognition methods, and by students for class projects in pattern recognition, machine learning, and statistics.
